


Einführung zum Computerlernen
Computerlernen ist ein aufregender Bereich, der immer mehr an Bedeutung gewinnt. Für Anfänger mag es zunächst einschüchternd erscheinen, aber mit der richtigen Einführung kann man sich schnell in dieses faszinierende Gebiet einarbeiten. In diesem Artikel werden wir uns mit dem Wesen des Computerlernens befassen, warum es wichtig ist und verschiedene Ansätze und Methoden, die verwendet werden.
Was ist Computerlernen und warum ist es wichtig?
Computerlernen bezieht sich auf die Fähigkeit eines Computers, aus Daten zu lernen und automatisch Muster und Zusammenhänge zu erkennen, ohne explizit programmiert zu werden. Im Gegensatz zu traditioneller Programmierung, bei der die Anweisungen klar vorgegeben werden, ermöglicht Computerlernen dem Computer, selbstständig zu lernen und Entscheidungen zu treffen.
Es ist wichtig, sich mit dem Computerlernen vertraut zu machen, da es zahlreiche Anwendungsbereiche gibt, in denen es eingesetzt werden kann. Zum Beispiel kann es in der Medizin verwendet werden, um Krankheiten zu diagnostizieren, in der Finanzwelt, um den Aktienmarkt vorherzusagen, und in der Automobilindustrie, um autonome Fahrzeuge zu entwickeln. In einer zunehmend datengetriebenen Welt ist das Verständnis des Computerlernens ein wertvolles Werkzeug, um bessere Entscheidungen zu treffen und neue Lösungen zu finden.
Verschiedene Ansätze und Methoden des Computerlernens
Es gibt verschiedene Ansätze und Methoden, mit denen Computerlernen umgesetzt werden kann. Hier sind einige der häufig verwendeten:
- Überwachtes Lernen: Bei dieser Methode werden dem Computer Beispieldaten bereitgestellt, bei denen sowohl die Eingabe als auch die erwartete Ausgabe bekannt sind. Der Computer lernt, die Muster in den Daten zu erkennen und kann dann Vorhersagen für neue, noch nicht gesehene Daten treffen.
- Unüberwachtes Lernen: Im Gegensatz zum überwachten Lernen werden dem Computer bei unüberwachtem Lernen keine erwarteten Ausgaben gegeben. Stattdessen sucht der Computer nach Mustern und Zusammenhängen in den Daten, ohne spezifische Anweisungen zu haben. Dies kann helfen, verborgene Strukturen und Erkenntnisse in den Daten aufzudecken.
- Verstärkungslernen: Beim verstärkenden Lernen wird der Computer mithilfe von Belohnungen und Bestrafungen trainiert. Der Computer lernt durch die Interaktion mit seiner Umgebung und erhält Feedback, ob seine Aktionen positiv oder negativ sind. Auf diese Weise kann der Computer seine Entscheidungen optimieren und bessere Ergebnisse erzielen.
Es ist wichtig zu beachten, dass Computerlernen ein iterativer Prozess ist, bei dem fortlaufend neue Daten analysiert und Modelle verbessert werden. Auch der Auswahl der richtigen Algorithmen und Modelle spielt eine entscheidende Rolle beim Erfolg des Computerlernens.
Insgesamt bietet das Computerlernen spannende Möglichkeiten und eröffnet neue Horizonte für die Lösung von komplexen Problemen. Für Anfänger ist es wichtig, einen soliden Einstieg in das Gebiet zu bekommen und sich mit den Grundlagen vertraut zu machen, um das volle Pot

Grundlagen des Computerlernens
Datensätze und Merkmale verstehen
Bevor man in die Welt des Computerlernens eintaucht, ist es wichtig, die Grundlagen zu verstehen. Ein wichtiger Aspekt des Computerlernens ist die Arbeit mit Datensätzen. Ein Datensatz ist eine Sammlung von Informationen, die der Computer analyseieren und daraus lernen kann. Es ist wichtig, einen geeigneten Datensatz auszuwählen, der die gewünschten Informationen enthält und gut strukturiert ist.
Zusätzlich zu den Datensätzen sind Merkmale von großer Bedeutung. Merkmale sind die Eigenschaften oder Variablen in einem Datensatz, die dabei helfen, Muster und Zusammenhänge zu erkennen. Beispielsweise könnten Merkmale in einem Datensatz zur Vorhersage von Hauspreisen die Anzahl der Zimmer, die Quadratmeterzahl und die Lage des Hauses sein. Ein Verständnis für die Merkmale und ihre Bedeutung ist entscheidend, um präzise Vorhersagen zu treffen.
Überwachte und unüberwachte Lernmethoden
Im Computerlernen gibt es verschiedene Methoden, um aus den vorhandenen Daten zu lernen. Ein wichtiger Ansatz ist das überwachte Lernen. Hierbei werden dem Computer Datensätze mit bekannten Eingaben und entsprechenden Ausgaben gegeben. Der Computer lernt dann, Muster und Zusammenhänge in den Daten zu erkennen, um Vorhersagen für neue, noch nicht gesehene Daten zu treffen. Dieser Ansatz eignet sich gut für Klassifikations- und Regressionsprobleme, bei denen der Computer bestimmte Kategorien zuordnen oder kontinuierliche Werte vorhersagen soll.
Ein weiterer Ansatz ist das unüberwachte Lernen. Hierbei werden dem Computer keine Ausgaben vorgegeben, sondern er sucht eigenständig nach Mustern und Zusammenhängen in den Daten. Der Fokus liegt hierbei darauf, versteckte Strukturen und Erkenntnisse aufzudecken. Unüberwachtes Lernen eignet sich gut für Clustering-Probleme, bei denen der Computer ähnliche Gruppen in den Daten identifiziert, oder für die Reduzierung der Dimensionalität von Datensätzen.
Es ist wichtig zu beachten, dass beide Ansätze ihre Vor- und Nachteile haben und je nach Anwendungsfall unterschiedlich geeignet sein können. Die Auswahl der geeigneten Lernmethode ist entscheidend für den Erfolg des Computerlernens.
Insgesamt bietet das Computerlernen spannende Möglichkeiten für Anfänger und eröffnet neue Horizonte. Es ist jedoch wichtig, die Grundlagen zu verstehen und eine solide Basis zu schaffen, um erfolgreich in dieses faszinierende Gebiet einzusteigen.
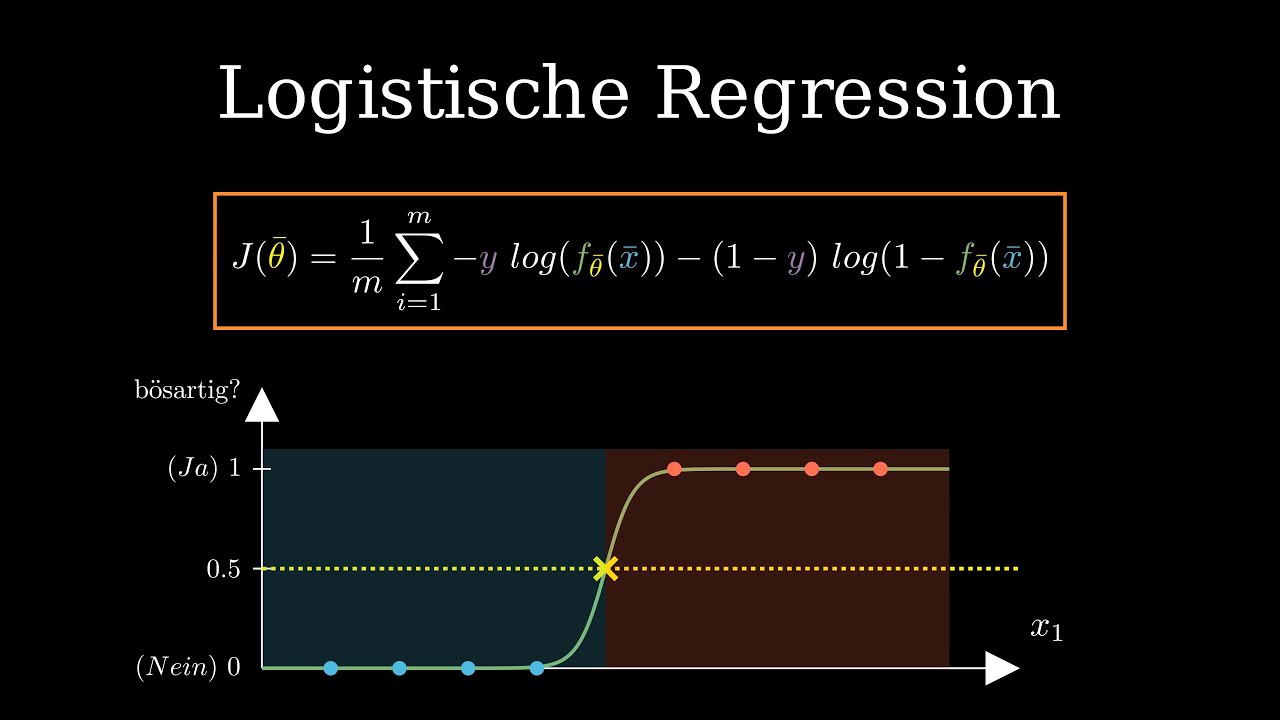
Algorithmen und Modelle
Lineare Regression und logistische Regression
Beim Computerlernen für Anfänger sind lineare Regression und logistische Regression zwei grundlegende Algorithmen, die häufig verwendet werden.
Die lineare Regression wird verwendet, um eine Linie zu finden, die am besten zu den vorhandenen Daten passt. Sie eignet sich gut für kontinuierliche Ausgaben, wie zum Beispiel die Vorhersage von Hauspreisen basierend auf bestimmten Merkmalen. Durch die Anpassung einer Geraden an die Daten kann die lineare Regression zukünftige Werte schätzen und Vorhersagen treffen.
Die logistische Regression hingegen wird verwendet, um Wahrscheinlichkeiten für binäre Ausgaben zu schätzen, wie zum Beispiel das Vorhersagen, ob ein E-Mail Spam ist oder nicht. Sie nutzt eine S-Kurve, um die Wahrscheinlichkeit der binären Ausgabe in Abhängigkeit von den Eingabemerkmale zu modellieren. Die logistische Regression ermöglicht eine einfache Interpretation der Ergebnisse und ist leicht zu verstehen.
k-Nearest Neighbors und Entscheidungsbäume
Zwei weitere Algorithmen, mit denen Anfänger im Computerlernen vertraut sein sollten, sind k-Nearest Neighbors und Entscheidungsbäume.
k-Nearest Neighbors (k-NN) ist ein einfacher Klassifikationsalgorithmus, der auf der Annahme basiert, dass ähnliche Dinge in einer ähnlichen Umgebung existieren. Das heißt, wenn ein neuer Datenpunkt klassifiziert werden soll, werden die k nächsten Nachbarn des Datenpunkts betrachtet und die Mehrheit ihrer Klassen bestimmt die Klassifizierung für den neuen Punkt. k-NN ist einfach zu implementieren, aber es erfordert die Wahl eines geeigneten k-Werts und kann empfindlich gegenüber Ausreißern sein.
Entscheidungsbäume sind eine weitere oft verwendete Methode im Computerlernen. Hierbei werden Entscheidungspunkte basierend auf Merkmalen erstellt, um schrittweise zu einer abschließenden Klassifizierung oder Vorhersage zu gelangen. Entscheidungsbäume sind leicht verständlich und interpretierbar, bieten jedoch auch die Möglichkeit der Überanpassung an die Trainingsdaten. Es gibt verschiedene Methoden wie Random Forests oder Gradient Boosting, um die Leistung von Entscheidungsbäumen zu verbessern und ihre Schwächen zu überwinden.
Es ist wichtig zu beachten, dass diese Algorithmen nur der Anfang sind und es viele andere Algorithmen und Modelle gibt, die im Computerlernen verwendet werden können. Die Wahl des richtigen Algorithmus hängt von der Art der Daten, dem Ziel der Analyse und anderen Faktoren ab. Mit der Zeit und Erfahrung werden Anfänger im Computerlernen lernen, welcher Algorithmus am besten für verschiedene Situationen geeignet ist.
Insgesamt bieten die Algorithmen und Modelle des Computerlernens vielfältige Möglichkeiten für Anfänger. Es ist wichtig, verschiedene Algorithmen zu erforschen, zu experimentieren und die Grundlagen zu verstehen, um erfolgreich in diesem Bereich zu sein. Mit Übung und Kontinuität können Anfänger allmählich ihre Fähigkeiten verbessern und in komplexeren Projekten erfolgreich Anwendung finden.
Evaluierung und Verbesserung des Modells
Trainings-, Validierungs- und Testdaten
Im Bereich des Computerlernens für Anfänger spielen Trainings-, Validierungs- und Testdaten eine wichtige Rolle bei der Evaluierung und Verbesserung des Modells. Die Trainingsdaten werden verwendet, um das Modell zu trainieren und die Gewichte anzupassen. Die Validierungsdaten dienen dazu, die Leistung des Modells während des Trainings zu überwachen und um Anpassungen vorzunehmen. Die Testdaten werden schließlich verwendet, um die endgültige Leistung des Modells zu bewerten und zu überprüfen, wie gut es auf neue, nicht gesehene Daten angewendet werden kann.
Es ist wichtig, dass die Daten für jede dieser drei Phasen unterschiedlich sind, um eine realistische Bewertung des Modells zu ermöglichen. Wenn die gleichen Daten für das Training, die Validierung und den Test verwendet werden, kann dies zu einem überoptimierten Modell führen, das gut auf den Trainingsdaten abschneidet, aber schlecht auf neuen Daten funktioniert.
Overfitting und Underfitting vermeiden
Ein weiteres wichtiges Konzept im Computerlernen für Anfänger ist das Vermeiden von Overfitting und Underfitting. Overfitting tritt auf, wenn das Modell zu stark an die Trainingsdaten angepasst ist und die Fähigkeit verliert, auf neuen Daten allgemeine Vorhersagen zu treffen. Underfitting hingegen tritt auf, wenn das Modell zu einfach ist und die Komplexität der Daten nicht erfasst.
Um Overfitting und Underfitting zu vermeiden, können verschiedene Techniken angewendet werden. Eine Möglichkeit besteht darin, die Komplexität des Modells anzupassen, indem beispielsweise die Anzahl der Ebenen in einem neuronalen Netzwerk verringert wird. Eine andere Möglichkeit besteht darin, eine Regularisierungstechnik wie das Hinzufügen von Dropout-Layern zu verwenden, um bestimmte Neuronen während des Trainings zu deaktivieren.
Darüber hinaus ist es wichtig, die Hyperparameter des Modells sorgfältig abzustimmen. Dies sind Parameter, die nicht aus den Trainingsdaten gelernt werden, sondern vom Benutzer festgelegt werden müssen. Beispiele für Hyperparameter sind die Lernrate, die Anzahl der Epochen und die Batch-Größe. Durch Experimentieren und Validierung der Leistung des Modells für verschiedene Hyperparameter-Werte kann ein besser angepasstes Modell erreicht werden.
Im Computerlernen für Anfänger ist es von entscheidender Bedeutung, Evaluierungstechniken zu verstehen und anzuwenden, um die Leistung des Modells zu verbessern. Durch die Verwendung separater Trainings-, Validierungs- und Testdaten und das Vermeiden von Overfitting und Underfitting können Anfänger lernen, wie sie ihre Modelle optimieren und zuverlässige Vorhersagen treffen können.
Mit der Zeit und Erfahrung können Anfänger im Computerlernen ihre Fähigkeiten weiterentwickeln und fortgeschrittenere Techniken wie Kreuzvalidierung, Ensemble-Modelle und neuronale Architekturen erkunden. Es ist jedoch wichtig, zunächst solide Grundlagen zu verstehen und die Grundprinzipien der Evaluierung und Verbesserung von Modellen zu beherrschen, um erfolgreich im Bereich des Computerlernens zu sein.
Anwendungen des Computerlernens
Bilderkennung und Objekterkennung
Computerlernen hat viele Anwendungen, von denen eine die Bilderkennung und Objekterkennung ist. Mithilfe von Machine-Learning-Algorithmen können Computer lernen, Bilder zu analysieren und darin enthaltene Objekte zu erkennen. Dies ist besonders nützlich in Bereichen wie der Medizin, wo Bilderkennung verwendet wird, um Krankheiten oder Anomalien auf Röntgenbildern oder MRT-Scans zu identifizieren. In der Automobilbranche wird Objekterkennung eingesetzt, um Fahrassistenzsysteme zu entwickeln, die Verkehrsschilder, Fußgänger oder andere Fahrzeuge erkennen können.
Sprach- und Textverarbeitung
Mit Hilfe von Machine Learning können Computer auch Sprache verstehen und Texte verarbeiten. Diese Technologie wird in Spracherkennungssystemen wie Siri oder Google Assistant eingesetzt, um gesprochene Worte in Text umzuwandeln und entsprechende Aktionen auszuführen. Textverarbeitung wird auch in automatisierten Chatbots verwendet, die in der Lage sind, Kundensupport zu leisten oder Fragen zu beantworten.
Anomalieerkennung und Betrugserkennung
Ein weiteres Anwendungsgebiet des Computerlernens ist die Anomalieerkennung und Betrugserkennung. Durch das Trainieren von Algorithmen mit großen Datensätzen kann das System Muster erkennen und abnormales Verhalten identifizieren. In der Finanzbranche wird diese Technologie verwendet, um betrügerische Transaktionen zu erkennen und zu verhindern. Auch im Bereich der Cybersecurity kann Anomalieerkennung eingesetzt werden, um verdächtige Aktivitäten oder Angriffe auf Netzwerke zu erkennen.
Automatisierung und Robotik
Computerlernen ermöglicht auch die Automatisierung von Aufgaben und die Entwicklung von Robotiksystemen. Durch das Trainieren von Robotern mit Machine-Learning-Algorithmen können sie bestimmte Aufgaben erlernen und ausführen, wie zum Beispiel das Sortieren von Objekten oder das Montieren von Komponenten in der Fertigungsindustrie. Dies erhöht die Effizienz und Genauigkeit bei repetitive Aufgaben und ermöglicht den Menschen, sich auf komplexere und kreative Aufgaben zu konzentrieren.
Empfehlungssysteme
Empfehlungssysteme sind ein weiteres prominentes Anwendungsgebiet des Computerlernens. Diese Systeme analysieren das Verhalten von Benutzern und stellen personalisierte Empfehlungen für Produkte, Filme, Musik oder Artikel bereit. Zum Beispiel verwendet Amazon ein Empfehlungssystem, das auf den vergangenen Käufen und dem Verhalten eines Benutzers basiert, um ähnliche Produkte vorzuschlagen, die für ihn interessant sein könnten.
Computerlernen bietet unzählige Möglichkeiten und hat das Potenzial, nahezu jede Branche zu revolutionieren. Für Anfänger im Bereich des Computerlernens ist es wichtig, die Grundlagen zu verstehen und sich mit den verschiedenen Anwendungen vertraut zu machen. Mit der richtigen Ausbildung und Erfahrung können Anfänger lernen, wie sie Machine-Learning-Modelle entwickeln und anwenden können, um Probleme in ihrem gewählten Bereich zu lösen und innovative Lösungen zu entwickeln.

Fazit
Computerlernen bietet unzählige Möglichkeiten und hat das Potenzial, nahezu jede Branche zu revolutionieren. Für Anfänger im Bereich des Computerlernens ist es wichtig, die Grundlagen zu verstehen und sich mit den verschiedenen Anwendungen vertraut zu machen.
Zusammenfassung der wichtigsten Konzepte des Computerlernens
Beim Einstieg in das Computerlernen sollten Anfänger einige wichtige Konzepte verstehen:
- Machine Learning-Algorithmen: Es gibt verschiedene Arten von Algorithmen, die verwendet werden können, um aus Daten zu lernen und Vorhersagen zu treffen. Dazu gehören überwachtes Lernen, unüberwachtes Lernen und verstärkendes Lernen.
- Datenvorbereitung: Bevor Daten in ein Machine-Learning-Modell eingespeist werden können, müssen sie gereinigt, transformiert und für die Analyse vorbereitet werden. Dies beinhaltet das Entfernen von Ausreißern, das Füllen von fehlenden Werten und das Codieren von kategorialen Variablen.
- Modellauswahl und -bewertung: Es gibt verschiedene Modelle, die für verschiedene Arten von Problemen geeignet sind. Die Auswahl des richtigen Modells hängt von den spezifischen Anforderungen und Daten ab. Die Leistung des Modells kann mithilfe von Metriken wie Genauigkeit, Präzision und Rückruf bewertet werden.
- Training und Evaluierung des Modells: Das Trainieren des Modells beinhaltet das Anpassen der Modellparameter an die Trainingsdaten. Nach dem Training muss das Modell mit neuen Daten getestet und evaluiert werden, um seine Leistungsfähigkeit zu bewerten.
Nächste Schritte zur Vertiefung des Wissens
Um das Wissen im Bereich des Computerlernens zu vertiefen, können Anfänger die folgenden Schritte unternehmen:
- Online-Ressourcen: Es gibt viele kostenlose Online-Kurse und Tutorials, die Anfängern helfen, die Grundlagen des Computerlernens zu verstehen und praktische Erfahrungen zu sammeln. Plattformen wie Coursera, Udemy und Kaggle bieten eine Vielzahl von Ressourcen für verschiedene Lernstufen.
- Praktische Projekte: Die Anwendung des Gelernten in praktischen Projekten ist eine effektive Möglichkeit, das Verständnis zu vertiefen. Anfänger können beispielsweise an Wettbewerben teilnehmen oder eigene Projekte zur Lösung realer Probleme erstellen.
- Bücher und Fachliteratur: Es gibt viele Bücher und wissenschaftliche Artikel, die sich mit den fortgeschritteneren Konzepten des Computerlernens befassen. Das Lesen solcher Literatur kann helfen, das Verständnis zu erweitern und komplexe Themen besser zu erfassen.
- Gemeinschaftsaktivitäten: Der Austausch mit anderen Lernenden und Experten kann wertvoll sein, um Fragen zu klären, Ideen auszutauschen und neue Perspektiven zu gewinnen. Teilnahme an lokalen Meetups, Foren und Online-Communities kann dabei helfen.
Es ist wichtig, geduldig und beständig zu sein, während man sich im Bereich des Computerlernens entwickelt. Mit einer Mischung aus Theorie und praktischer Anwendung können Anfänger ihre Fähigkeiten verbessern und innovative Lösungen entwickeln.









